InfoTree is a data structure in Lean 4 that records each tactic, the state before each tactic was applied (goals and hypotheses before) and the state after each tactic was applied (goals and hypotheses after). In Lean 4, parsing the InfoTree is the only way to get a list of tactics and their corresponding effect on the proof.
Taking a look into the general shape of the InfoTree
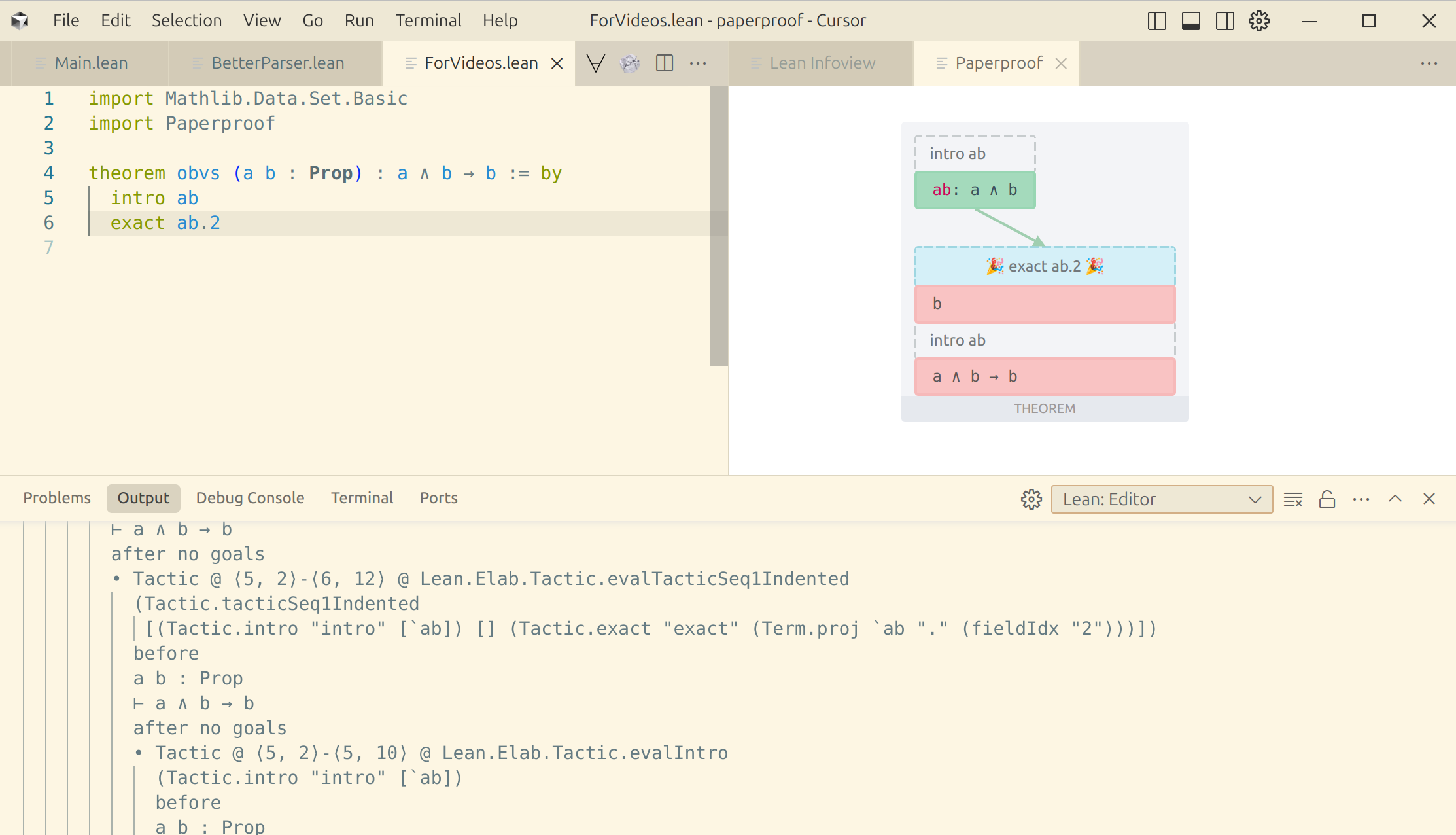
Suppose we're parsing the InfoTree of theorem obvs from the screenshot below. We can pretty-print the InfoTree of this proof by writing dbg_trace <- snapshot.infoTree.format, going to the VSCode's Output pane, and selecting the Lean:Editor output channel.
Pretty-printing the InfoTree will get you the following 79-line output:
Click to expand JSON
• command @ ⟨4, 0⟩-⟨6, 12⟩ @ Lean.Elab.Command.elabDeclaration
• Prop : Type @ ⟨4, 20⟩-⟨4, 24⟩ @ Lean.Elab.Term.elabProp
• a (isBinder := true) : Prop @ ⟨4, 14⟩-⟨4, 15⟩
• Prop : Type @ ⟨4, 20⟩-⟨4, 24⟩ @ Lean.Elab.Term.elabProp
• b (isBinder := true) : Prop @ ⟨4, 16⟩-⟨4, 17⟩
• a ∧ b → b : Prop @ ⟨4, 28⟩-⟨4, 37⟩ @ Lean.Elab.Term.elabArrow
• a ∧ b : Prop @ ⟨4, 28⟩-⟨4, 33⟩ @ «_aux_Init_Notation___macroRules_term_∧__1»
• Macro expansion
a ∧ b
===>
And✝ a b
• a ∧ b : Prop @ ⟨4, 28⟩†-⟨4, 33⟩† @ Lean.Elab.Term.elabApp
• [.] And✝ : some Sort.{?_uniq.6} @ ⟨4, 28⟩†-⟨4, 33⟩†
• And : Prop → Prop → Prop @ ⟨4, 28⟩†-⟨4, 33⟩†
• a : Prop @ ⟨4, 28⟩-⟨4, 29⟩ @ Lean.Elab.Term.elabIdent
• [.] a : some Prop @ ⟨4, 28⟩-⟨4, 29⟩
• a : Prop @ ⟨4, 28⟩-⟨4, 29⟩
• b : Prop @ ⟨4, 32⟩-⟨4, 33⟩ @ Lean.Elab.Term.elabIdent
• [.] b : some Prop @ ⟨4, 32⟩-⟨4, 33⟩
• b : Prop @ ⟨4, 32⟩-⟨4, 33⟩
• b : Prop @ ⟨4, 36⟩-⟨4, 37⟩ @ Lean.Elab.Term.elabIdent
• [.] b : some Sort.{?_uniq.7} @ ⟨4, 36⟩-⟨4, 37⟩
• b : Prop @ ⟨4, 36⟩-⟨4, 37⟩
• obvs (isBinder := true) : ∀ (a b : Prop), a ∧ b → b @ ⟨4, 8⟩-⟨4, 12⟩
• a (isBinder := true) : Prop @ ⟨4, 14⟩-⟨4, 15⟩
• b (isBinder := true) : Prop @ ⟨4, 16⟩-⟨4, 17⟩
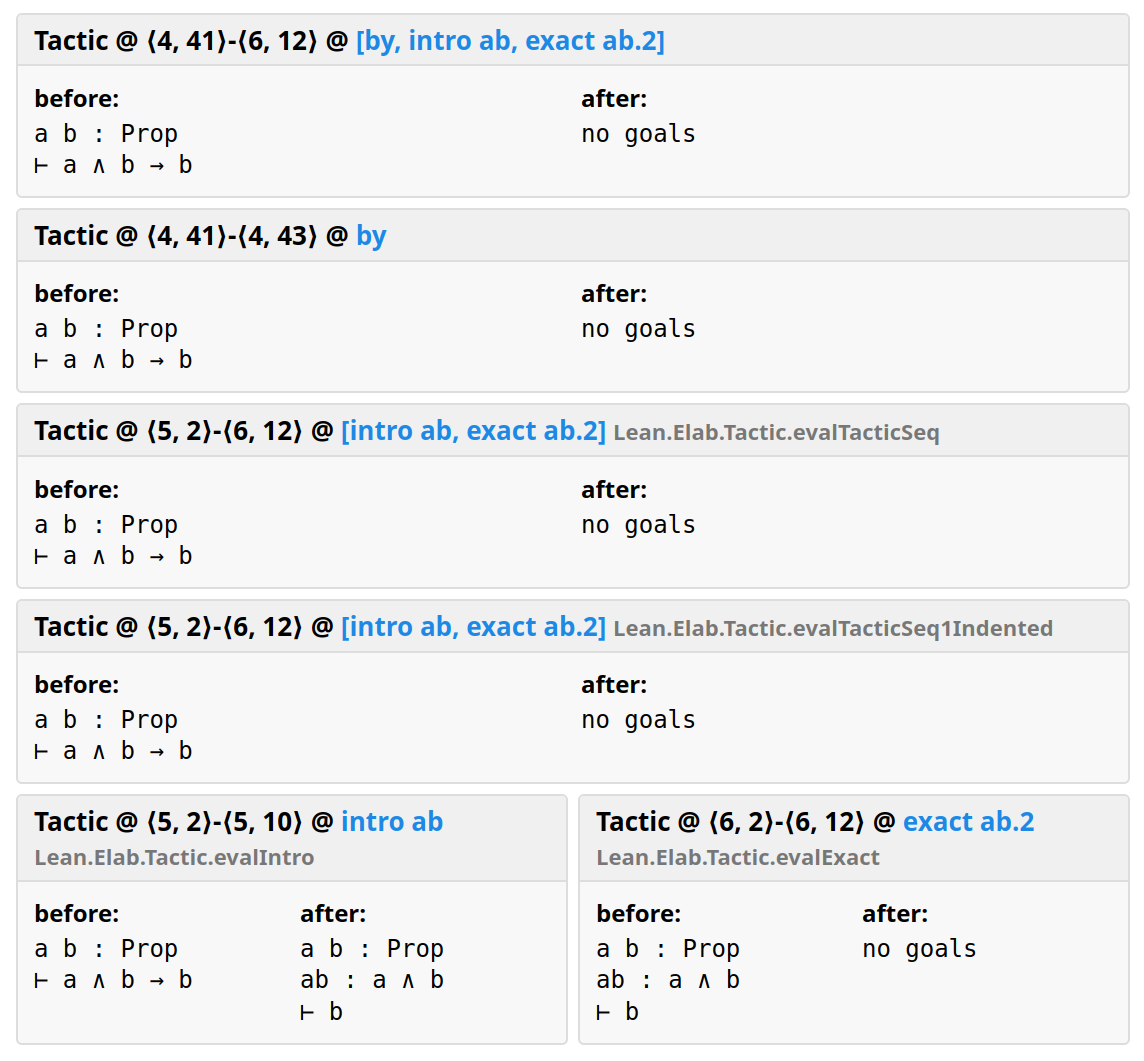
• Tactic @ ⟨4, 41⟩-⟨6, 12⟩
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab]) [] (Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨4, 41⟩-⟨4, 43⟩
"by"
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨5, 2⟩-⟨6, 12⟩ @ Lean.Elab.Tactic.evalTacticSeq
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab]) [] (Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨5, 2⟩-⟨6, 12⟩ @ Lean.Elab.Tactic.evalTacticSeq1Indented
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab]) [] (Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨5, 2⟩-⟨5, 10⟩ @ Lean.Elab.Tactic.evalIntro
(Tactic.intro "intro" [`ab])
before
a b : Prop
⊢ a ∧ b → b
after
a b : Prop
ab : a ∧ b
⊢ b
• ab (isBinder := true) : a ∧ b @ ⟨5, 8⟩-⟨5, 10⟩
• Tactic @ ⟨6, 2⟩-⟨6, 12⟩ @ Lean.Elab.Tactic.evalExact
(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))
before
a b : Prop
ab : a ∧ b
⊢ b
after no goals
• ab.right : b @ ⟨6, 8⟩-⟨6, 12⟩ @ Lean.Elab.Term.elabProj
• [.] ab : some _uniq.10 @ ⟨6, 8⟩-⟨6, 10⟩
• ab : a ∧ b @ ⟨6, 8⟩-⟨6, 10⟩
• @And.right : ∀ {a b : Prop}, a ∧ b → b @ ⟨6, 11⟩-⟨6, 12⟩
• obvs (isBinder := true) : ∀ (a b : Prop), a ∧ b → b @ ⟨4, 8⟩-⟨4, 12⟩
This output starts from the command @ ⟨4, 0⟩-⟨6, 12⟩ @ Lean.Elab.Command.elabDeclaration line. This is expected, because the command syntax category in Lean 4 includes traditional commands (#check, #explode, etc.), import statements, and, finally, theorem statements (our case). As can be guessed, the numbers in brackets indicate line and character numbers - this line tells us our snapshot consists of a command, and this command spans from ⟨line 4, character 0⟩ to ⟨line 6, character 12⟩.
Nested in this command node you see the various constituents of this command, sometimes repeated, and in no particular order: Prop, a, Prop, b, a ∧ b → b, obvs, a, b, Tactic ["by", "intro ab", "exact ab.2"], obvs. Notice how all of the root node children have ⟨line, character⟩ pairs that are nested under the root's ⟨4, 0⟩-⟨6, 12⟩ position - this pattern will repeat throughout the InfoTree, but doesn't always hold.
Parsing each InfoTree.node
Below you see the InfoTree data structure as defined in Lean source code.
inductive InfoTree where
| context (i : PartialContextInfo) (t : InfoTree)
| node (i : Info) (children : PersistentArray InfoTree)
| hole (mvarId : MVarId)
inductive Info where
| ofTacticInfo (i : TacticInfo)
| ofTermInfo (i : TermInfo)
| ofCommandInfo (i : CommandInfo)
| ofMacroExpansionInfo (i : MacroExpansionInfo)
| ofOptionInfo (i : OptionInfo)
| ofFieldInfo (i : FieldInfo)
| ofCompletionInfo (i : CompletionInfo)
| ofUserWidgetInfo (i : UserWidgetInfo)
| ofCustomInfo (i : CustomInfo)
| ofFVarAliasInfo (i : FVarAliasInfo)
| ofFieldRedeclInfo (i : FieldRedeclInfo)
| ofOmissionInfo (i : OmissionInfo)
Whenever you see a new • in the InfoTree pretty-printing output, this indicates a new InfoTree.node. All types of nodes (Info.ofTacticInfo, Info.ofTermInfo, Info.ofCommandInfo) are pretty-printed in different ways, however there are some commonalities. Let's list some examples of how to parse this output, going from the first line in our pretty-printed InfoTree.
• {expr} {?isBinder} : {type} @ {position} @ {?elaborator} • a ∧ b → b : Prop @ ⟨4, 28⟩-⟨4, 37⟩ @ Lean.Elab.Term.elabArrow
When the line starts from what it is (in our case it's a ∧ b → b), it means we're dealing with Info.ofTermInfo. The way TermInfo is printed is as follows:
• Tactic @ {position} @ {?elaborator} {syntax} before {goalsBefore} after {goalsAfter} • Tactic @ ⟨4, 41⟩-⟨6, 12⟩ (Term.byTactic "by" (Tactic.tacticSeq (Tactic.tacticSeq1Indented [(Tactic.intro "intro" [`ab]) [] (Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))) before a b : Prop ⊢ a ∧ b → b after no goals
When the line starts from Tactic, it means we're dealing with TacticInfo - the most interesting InfoTree node, we'll dedicate the next section to this node. The way TacticInfo is printed is as follows:
Tactic @
{formatStxRange ctx info.stx} @
{if info.elaborator.isAnonymous then "" else info.elaborator}" \n
{info.stx} \n
before \n
{goalsBefore} \n
after \n
{goalsAfter}
TacticInfo: the most interesting InfoTree node
As can be seen from the InfoTree inductive, each node consists of Info, and, optionally, children (an array of other InfoTrees).
inductive InfoTree where
| context (i : PartialContextInfo) (t : InfoTree)
| node (i : Info) (children : PersistentArray InfoTree)
| hole (mvarId : MVarId)
In case with TacticInfo, this array of children is typically an array of other tactic nodes ([TacticInfo, TacticInfo, TacticInfo]).
Taking our first TacticInfo as an example (I shortened the {syntax} part to make it more explicit), we can see it represents some kind of a fake mega-tactic consisting of all of our real tactics, and telling us the proof state before and after all of our real tactics were applied.
Tactic @ ⟨4, 41⟩-⟨6, 12⟩
["by", "intro ab", "exact ab.2"]
before
a b : Prop
⊢ a ∧ b → b
after
no goals
Let's draw a tree indicating the children and descendants of this fake mega-tactic.
You can see that the real actual tactics that we are generally after are the leaf nodes in the InfoTree. The obvious question is - should we always just go for the leaf nodes, are intermediate nodes useful for something?
Fancy proofs
Let complicate our proof a bit by inserting a have:
theorem obvs (a b : Prop) : a ∧ b → b := by
intro ab
have just_b := by
exact ab.2
exact just_b
Pretty-printing the InfoTree of this proof will get you the following 512-line output:
Click to expand JSON
• command @ ⟨6, 0⟩-⟨10, 14⟩ @ Lean.Elab.Command.elabDeclaration
• Prop : Type @ ⟨6, 20⟩-⟨6, 24⟩ @ Lean.Elab.Term.elabProp
• a (isBinder := true) : Prop @ ⟨6, 14⟩-⟨6, 15⟩
• Prop : Type @ ⟨6, 20⟩-⟨6, 24⟩ @ Lean.Elab.Term.elabProp
• b (isBinder := true) : Prop @ ⟨6, 16⟩-⟨6, 17⟩
• a ∧ b → b : Prop @ ⟨6, 28⟩-⟨6, 37⟩ @ Lean.Elab.Term.elabArrow
• a ∧ b : Prop @ ⟨6, 28⟩-⟨6, 33⟩ @ «_aux_Init_Notation___macroRules_term_∧__1»
• Macro expansion
a ∧ b
===>
And✝ a b
• a ∧ b : Prop @ ⟨6, 28⟩†-⟨6, 33⟩† @ Lean.Elab.Term.elabApp
• [.] And✝ : some Sort.{?_uniq.6} @ ⟨6, 28⟩†-⟨6, 33⟩†
• And : Prop → Prop → Prop @ ⟨6, 28⟩†-⟨6, 33⟩†
• a : Prop @ ⟨6, 28⟩-⟨6, 29⟩ @ Lean.Elab.Term.elabIdent
• [.] a : some Prop @ ⟨6, 28⟩-⟨6, 29⟩
• a : Prop @ ⟨6, 28⟩-⟨6, 29⟩
• b : Prop @ ⟨6, 32⟩-⟨6, 33⟩ @ Lean.Elab.Term.elabIdent
• [.] b : some Prop @ ⟨6, 32⟩-⟨6, 33⟩
• b : Prop @ ⟨6, 32⟩-⟨6, 33⟩
• b : Prop @ ⟨6, 36⟩-⟨6, 37⟩ @ Lean.Elab.Term.elabIdent
• [.] b : some Sort.{?_uniq.7} @ ⟨6, 36⟩-⟨6, 37⟩
• b : Prop @ ⟨6, 36⟩-⟨6, 37⟩
• obvs (isBinder := true) : ∀ (a b : Prop), a ∧ b → b @ ⟨6, 8⟩-⟨6, 12⟩
• a (isBinder := true) : Prop @ ⟨6, 14⟩-⟨6, 15⟩
• b (isBinder := true) : Prop @ ⟨6, 16⟩-⟨6, 17⟩
• Tactic @ ⟨6, 41⟩-⟨10, 14⟩
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab])
[]
(Tactic.tacticHave_
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented [(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))))))
[]
(Tactic.exact "exact" `just_b)])))
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨6, 41⟩-⟨6, 43⟩
"by"
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨7, 2⟩-⟨10, 14⟩ @ Lean.Elab.Tactic.evalTacticSeq
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab])
[]
(Tactic.tacticHave_
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented [(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))))))
[]
(Tactic.exact "exact" `just_b)]))
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨7, 2⟩-⟨10, 14⟩ @ Lean.Elab.Tactic.evalTacticSeq1Indented
(Tactic.tacticSeq1Indented
[(Tactic.intro "intro" [`ab])
[]
(Tactic.tacticHave_
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented [(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))))))
[]
(Tactic.exact "exact" `just_b)])
before
a b : Prop
⊢ a ∧ b → b
after no goals
• Tactic @ ⟨7, 2⟩-⟨7, 10⟩ @ Lean.Elab.Tactic.evalIntro
(Tactic.intro "intro" [`ab])
before
a b : Prop
⊢ a ∧ b → b
after
a b : Prop
ab : a ∧ b
⊢ b
• ab (isBinder := true) : a ∧ b @ ⟨7, 8⟩-⟨7, 10⟩
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ Lean.Parser.Tactic._aux_Init_Tactics___macroRules_Lean_Parser_Tactic_tacticHave__1
(Tactic.tacticHave_
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented [(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))))))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Parser.Tactic._aux_Init_Tactics___macroRules_Lean_Parser_Tactic_tacticRefine_lift__1
(Tactic.tacticRefine_lift_
"refine_lift"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented [(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_")))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalFocus
(Tactic.focus
"focus"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.paren
"("
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])]))
")")])))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalFocus
"focus"
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalTacticSeq
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.paren
"("
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])]))
")")]))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalTacticSeq1Indented
(Tactic.tacticSeq1Indented
[(Tactic.paren
"("
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])]))
")")])
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalParen
(Tactic.paren
"("
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])]))
")")
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalTacticSeq
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])]))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalTacticSeq1Indented
(Tactic.tacticSeq1Indented
[(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
";"
(Tactic.rotateRight "rotate_right" [])])
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalRefine
(Tactic.refine
"refine"
(Term.noImplicitLambda
"no_implicit_lambda%"
(Term.have
"have"
(Term.haveDecl
(Term.haveIdDecl
(Term.haveId `just_b)
[]
[]
":="
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))))
";"
(Term.syntheticHole "?" "_"))))
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• let_fun just_b := ab.right;
?m.20 just_b : b @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Term.elabNoImplicitLambda
• let_fun just_b := ab.right;
?m.20 just_b : b @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Term.expandHave
• Macro expansion
have just_b := by exact ab.2;
?_
===>
let_fun just_b := by exact ab.2;
?_
• let_fun just_b := ab.right;
?m.20 just_b : b @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Term.elabLetFunDecl
• b : Prop @ ⟨8, 7⟩†-⟨8, 13⟩† @ Lean.Elab.Term.elabHole
• Tactic @ ⟨8, 17⟩-⟨9, 14⟩
(Term.byTactic
"by"
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])))
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after no goals
• Tactic @ ⟨8, 17⟩-⟨8, 19⟩
"by"
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ Lean.Elab.Tactic.evalTacticSeq
(Tactic.tacticSeq
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))]))
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ Lean.Elab.Tactic.evalTacticSeq1Indented
(Tactic.tacticSeq1Indented
[(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))])
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ Lean.Elab.Tactic.evalExact
(Tactic.exact "exact" (Term.proj `ab "." (fieldIdx "2")))
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after no goals
• ab.right : b @ ⟨9, 10⟩-⟨9, 14⟩ @ Lean.Elab.Term.elabProj
• [.] ab : some ?_uniq.16 @ ⟨9, 10⟩-⟨9, 12⟩
• ab : a ∧ b @ ⟨9, 10⟩-⟨9, 12⟩
• @And.right : ∀ {a b : Prop}, a ∧ b → b @ ⟨9, 13⟩-⟨9, 14⟩
• just_b (isBinder := true) : b @ ⟨8, 7⟩-⟨8, 13⟩
• ?m.19 : b @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Term.elabSyntheticHole
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalTacticSeq1Indented
";"
before
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩†-⟨9, 14⟩† @ Lean.Elab.Tactic.evalRotateRight
(Tactic.rotateRight "rotate_right" [])
before
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨10, 2⟩-⟨10, 14⟩ @ Lean.Elab.Tactic.evalExact
(Tactic.exact "exact" `just_b)
before
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
after no goals
• just_b : b @ ⟨10, 8⟩-⟨10, 14⟩ @ Lean.Elab.Term.elabIdent
• [.] just_b : some [mdata noImplicitLambda:1 _uniq.10] @ ⟨10, 8⟩-⟨10, 14⟩
• just_b : b @ ⟨10, 8⟩-⟨10, 14⟩
• obvs (isBinder := true) : ∀ (a b : Prop), a ∧ b → b @ ⟨6, 8⟩-⟨6, 12⟩
Stripping away excessive nesting, we get to the following point - the fake all-encompassing mega-tactic has 3 TacticInfo children: intro ab, have just_b := ..., and exact just_b.
You can see the cleaned-up data structure here:
Click to expand JSON
• Tactic @ ⟨7, 2⟩-⟨10, 14⟩ @ [intro ab, have just_b := by exact ab.2; exact just_b] @ Lean.Elab.Tactic.evalTacticSeq1Indented
before
a b : Prop
⊢ a ∧ b → b
after
no goals
• Tactic @ ⟨7, 2⟩-⟨7, 10⟩ @ intro ab @ Lean.Elab.Tactic.evalIntro
before
a b : Prop
⊢ a ∧ b → b
after
a b : Prop
ab : a ∧ b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ have just_b := by exact ab.2 @ Lean.Parser.Tactic._aux_Init_Tactics___macroRules_Lean_Parser_Tactic_tacticHave__1
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [refine_lift have just_b := by exact ab.2] @ Lean.Parser.Tactic._aux_Init_Tactics___macroRules_Lean_Parser_Tactic_tacticRefine_lift__1
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ focus [(refine no_implicit_lambda have just_b := by exact ab.2 _, rotate_right] @ Lean.Elab.Tactic.evalFocus
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ focus @ Lean.Elab.Tactic.evalFocus
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [refine no_implicit_lambda, have just_b := by exact ab.2; rotate_right] @ Lean.Elab.Tactic.evalTacticSeq
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [(refine no_imlicit_lambda have just_b := by exact ab.2 _, rotate_right)] @ Lean.Elab.Tactic.evalTacticSeq1Indented
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [(refine no_implicit_lambda have just_b := by exact ab.2 _, rotate_right)] @ Lean.Elab.Tactic.evalParen
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [refine no_implicit_lambda have just_b := by exact ab.2 _, rotate_right] @ Lean.Elab.Tactic.evalTacticSeq
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [refine no_implicit_lambda have just_b := by exact ab.2 _, rotate_right] @ Lean.Elab.Tactic.evalTacticSeq1Indented
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ [refine no_implicit_lambda have := by exact ab.2 _] @ Lean.Elab.Tactic.evalRefine
before
a b : Prop
ab : a ∧ b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨8, 17⟩-⟨9, 14⟩ @ [by exact ab.2]
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after
no goals
• Tactic @ ⟨8, 17⟩-⟨8, 19⟩ @ by
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after
no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ [exact ab.2] @ Lean.Elab.Tactic.evalTacticSeq
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after
no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ [exact ab.2] @ Lean.Elab.Tactic.evalTacticSeq1Indented
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after
no goals
• Tactic @ ⟨9, 4⟩-⟨9, 14⟩ @ exact ab.2 @ Lean.Elab.Tactic.evalExact
before
a b : Prop
ab : a ∧ b
⊢ ?m.16
after
no goals
• Tactic @ ⟨8, 2⟩-⟨9, 14⟩ @ rotate_right @ Lean.Elab.Tactic.evalRotateRight
before
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
after
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
• Tactic @ ⟨10, 2⟩-⟨10, 14⟩ @ exact just_b @ Lean.Elab.Tactic.evalExact
before
a b : Prop
ab : a ∧ b
just_b : b
⊢ b
after
no goals
The first node (intro ab) and the third node (exact just_b) are leaf nodes, and give us clear before/after states. The second node (have just_b := ...) is an intermediate node, and contains many descendants - of which the leaf nodes are the most useful.
Where is the InfoTree created?
We are most interested in Info.ofTacticInfo InfoTrees, so let's look into the place where those are created.
What you should attend to is the withTacticInfoContext stx doBlock function. You can see its implementation below:
def withTacticInfoContext (stx : Syntax) (doBlock : TacticM α) : TacticM α := do
let mctxBefore ← getMCtx
let goalsBefore ← getUnsolvedGoals
let initialTacticInfo : TacticM Info := do
return Info.ofTacticInfo {
elaborator := (← read).elaborator
mctxBefore := mctxBefore
goalsBefore := goalsBefore
stx := stx
mctxAfter := (← getMCtx)
goalsAfter := (← getUnsolvedGoals)
}
withInfoContext doBlock initialTacticInfo
What withTacticInfoContent stx doBlock function is doing is: 1. retrieve the current getUnsolvedGoals (and put them into .goalsBefore) 2. execute the doBlock 3. retrieve the current getUnsolvedGoals (and put them into .goalsAfter).
There are two places where this function gets executed - the default place that's shared by all tactics (evalTactic function), and particular tactic implementation that do some handling on top of that.
Where is the InfoTree created: Default Place
If you read the "Overview" chapter in "Metaprogramming In Lean" textbook (link), you might remember the process of elaboration in Lean is as follows: 1. apply a relevant syntax rule ("let a := 2" ➤ Syntax) 2. apply all macros in a loop (Syntax ➤ Syntax) 3. apply a single elab (Syntax ➤ Expr)
Function evalTactic() is where the tactic nodes in our InfoTree get created. Coincidentally, function evalTactic() is a function where the elaboration process described above happens.
You can check out the full implementation of this function in Lean 4 repo (link). Here is a shorter version of that function, where I excluded all macro handling:
partial def evalTactic (stx : Syntax) : TacticM Unit := do
match stx with
| .node _ k _ =>
...
expandEval s macros evalFns #[]
| .missing => pure ()
| _ => throwError m!"unexpected tactic{indentD stx}"
where
...
expandEval (s : SavedState) (macros : List _) (evalFns : List _) (failures : Array EvalTacticFailure) : TacticM Unit :=
match macros with
| [] => eval s evalFns failures
| m :: ms => ...
eval (s : SavedState) (evalFns : List _) (failures : Array EvalTacticFailure) : TacticM Unit := do
match evalFns with
| [] => throwExs failures
| evalFn::evalFns => do
withTacticInfoContext stx do
evalFn.value stx
Even if you create your own tactic, it will be producing InfoTrees by default, because all tactics go through the elaboration process in def evalTactics, and def evalTactics does create InfoTrees internally.
In the evalTactic above I removed all the macro handling, but macros are everywhere, and it's interesting how macros are handled in the InfoTree. Let's create a brand new tactic of our own, and two macros:
open Lean Elab Tactic Meta
syntax (name := xxx) "red" : tactic
syntax (name := yyy) "green" : tactic
syntax (name := zzz) "blue" : tactic
@[macro xxx] def redMacro : Macro := λ stx =>
match stx with
| _ => `(tactic| green)
@[macro yyy] def greenMacro : Macro := λ stx =>
match stx with
| _ => `(tactic| blue)
-- This is our tactic.
-- All it does is it creates a new hypothesis `cute: True`.
@[tactic zzz] def blueElab : Lean.Elab.Tactic.Tactic := λ stx =>
withMainContext do
let trueExpr := mkConst `True
liftMetaTactic fun mvarId => do
-- Create a new hypothesis `cute: True`
let mvarIdNew ← mvarId.assert `cute trueExpr (mkConst `True.intro)
let (_, mvarIdFinal) ← mvarIdNew.intro1P
return [mvarIdFinal]
As a reminder about how elaboration in Lean works:
we write "red" in our proof
➤ def redMacro turns "red" into "green" ➤ def greenMacro turns "green" into "blue"
def blueElab gets executed
theorem hello : False := by
red
Now, let's see what the InfoTree that we get by hovering above the theorem hello looks like. Here is the following 53-line InfoTree output:
We can see it evalTactic creates a separate InfoTree tactic node per each macro transformation. The tactic we wrote ("red") is the parent node, while the tactic that was actually applied after all the macros ("blue") is its innermost child! This is, again, the case where leaf nodes of the InfoTree carry the real weight.
Where is the InfoTree created: Additional Places
Some tactics like to add their own InfoTree nodes on top of the default InfoTree creation that we get from the elaboration.
Consider the implementation of the rw tactic (link):
def withRWRulesSeq (token : Syntax) (rwRulesSeqStx : Syntax) (x : (symm : Bool) → (term : Syntax) → TacticM Unit) : TacticM Unit := do
let lbrak := rwRulesSeqStx[0]
let rules := rwRulesSeqStx[1].getArgs
-- show initial state up to (incl.) `[`
withTacticInfoContext (mkNullNode #[token, lbrak]) (pure ())
let numRules := (rules.size + 1) / 2
for i in [:numRules] do
let rule := rules[i * 2]!
let sep := rules.getD (i * 2 + 1) Syntax.missing
-- show rule state up to (incl.) next `,`
withTacticInfoContext (mkNullNode #[rule, sep]) do
...
x symm term
...
Given the theorem below, we sould normally only see the before and after state for the full rw [add_assoc, add_comm] line.
theorem ok : 2 + 3 + 4 = 666 := by
rw [add_assoc, add_comm]
But because rw adds additional withTacticInfoContext stx doBlock after each rule is applied, we get rw [add_assoc] (and proof state before and after) and rw [ass_comm] (and proof state before and after):